Enhance your memory system with graph-based knowledge representation and retrieval
Mem0 now supports Graph Memory.
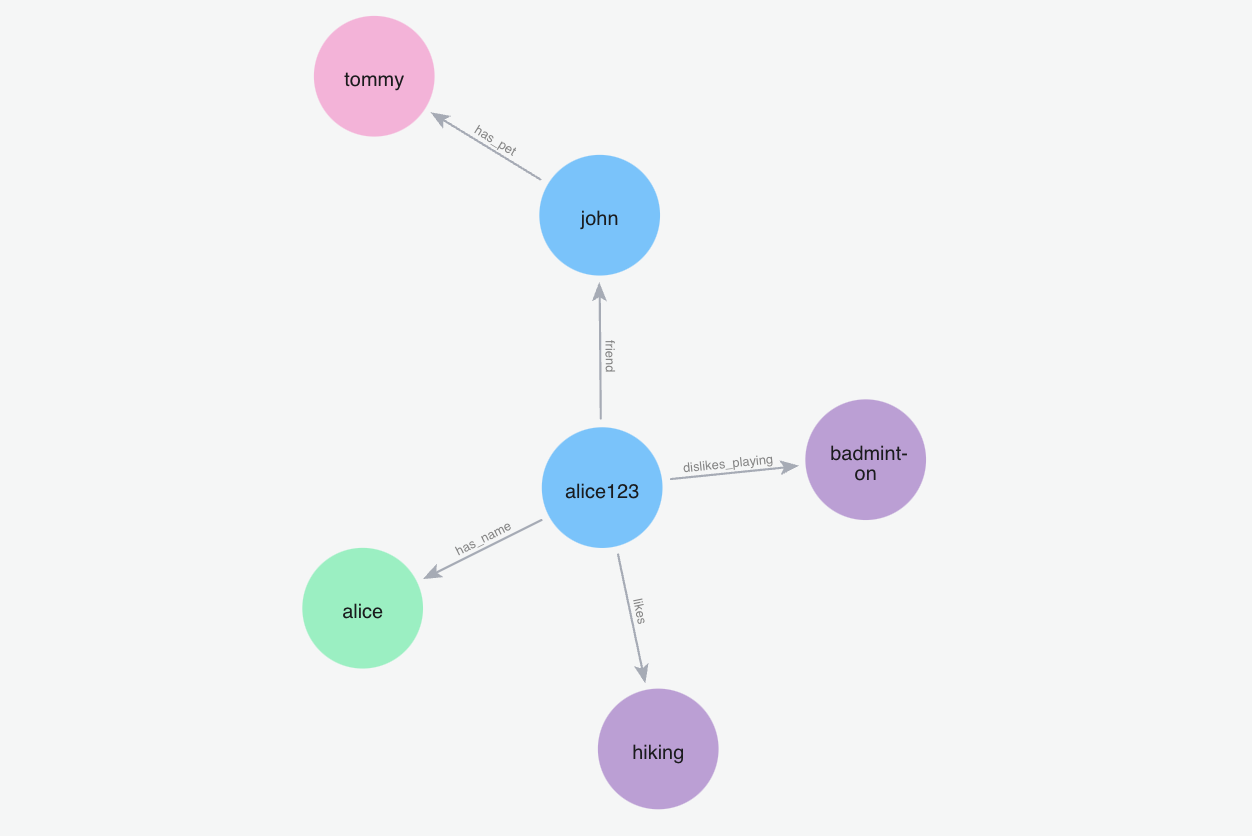
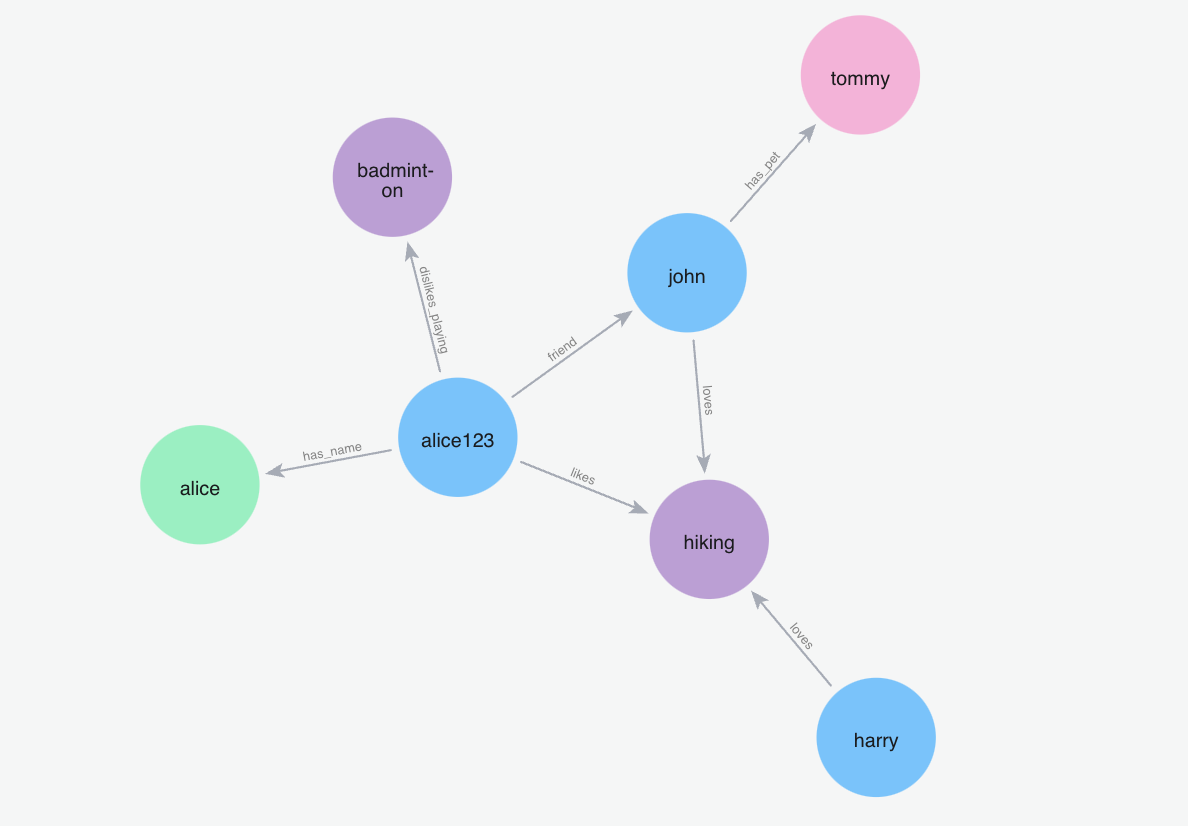
With Graph Memory, users can now create and utilize complex relationships between pieces of information, allowing for more nuanced and context-aware responses.
This integration enables users to leverage the strengths of both vector-based and graph-based approaches, resulting in more accurate and comprehensive information retrieval and generation.
To initialize Graph Memory you’ll need to set up your configuration with graph
store providers. Currently, we support Neo4j, Memgraph, Neptune Analytics, and Kuzu as graph store providers.
If you are using Neo4j locally, then you need to install APOC plugins.
User can also customize the LLM for Graph Memory from the Supported LLM list with three levels of configuration:
Main Configuration: If llm is set in the main config, it will be used for all graph operations.
Graph Store Configuration: If llm is set in the graph_store config, it will override the main config llm and be used specifically for graph operations.
Default Configuration: If no custom LLM is set, the default LLM (gpt-4o-2024-08-06) will be used for all graph operations.
docker run -p 7687:7687 memgraph/memgraph-mage:latest --schema-info-enabled=True
The --schema-info-enabled flag is set to True for more performant schema
generation.Additional information can be found on Memgraph
documentation.User can also customize the LLM for Graph Memory from the Supported LLM list with three levels of configuration:
Main Configuration: If llm is set in the main config, it will be used for all graph operations.
Graph Store Configuration: If llm is set in the graph_store config, it will override the main config llm and be used specifically for graph operations.
Default Configuration: If no custom LLM is set, the default LLM (gpt-4o-2024-08-06) will be used for all graph operations.
Mem0 now supports Amazon Neptune Analytics as a graph store provider. This integration allows you to use Neptune Analytics for storing and querying graph-based memories.You can use Neptune Analytics as part of an Amazon tech stack Setup AWS Bedrock, AOSS, and Neptune
The Neptune memory store uses AWS LangChain Python API to connect to Neptune instances. For additional configuration options for connecting to your Amazon Neptune Analytics instance see AWS LangChain API documentation.
Copy
Ask AI
from mem0 import Memory# Provided neptune-graph instance must have the same vector dimensions as the embedder provider.config = { "graph_store": { "provider": "neptune", "config": { "endpoint": "neptune-graph://<GRAPH_ID>", }, },}m = Memory.from_config(config_dict=config)
Kuzu is a fully local in-process graph database system that runs openCypher queries.
Kuzu comes embedded into the Python package and there is no additional setup required.Kuzu needs a path to a file where it will store the graph database. For example:
Mem0 with Graph Memory supports “user_id”, “agent_id”, and “run_id” parameters. You can use any combination of these to organize your memories. Use “userId”, “agentId”, and “runId” in NodeSDK.
Copy
Ask AI
# Using only user_idm.add("I like pizza", user_id="alice")# Using both user_id and agent_idm.add("I like pizza", user_id="alice", agent_id="food-assistant")# Using all three parameters for maximum organizationm.add("I like pizza", user_id="alice", agent_id="food-assistant", run_id="session-123")
# Get all memories for a userm.get_all(user_id="alice")# Get all memories for a specific agent belonging to a userm.get_all(user_id="alice", agent_id="food-assistant")# Get all memories for a specific run/sessionm.get_all(user_id="alice", run_id="session-123")# Get all memories for a specific agent and run combinationm.get_all(user_id="alice", agent_id="food-assistant", run_id="session-123")
# Search memories for a userm.search("tell me my name.", user_id="alice")# Search memories for a specific agent belonging to a userm.search("tell me my name.", user_id="alice", agent_id="food-assistant")# Search memories for a specific run/sessionm.search("tell me my name.", user_id="alice", run_id="session-123")# Search memories for a specific agent and run combinationm.search("tell me my name.", user_id="alice", agent_id="food-assistant", run_id="session-123")
# Delete all memories for a userm.delete_all(user_id="alice")# Delete all memories for a specific agent belonging to a userm.delete_all(user_id="alice", agent_id="food-assistant")
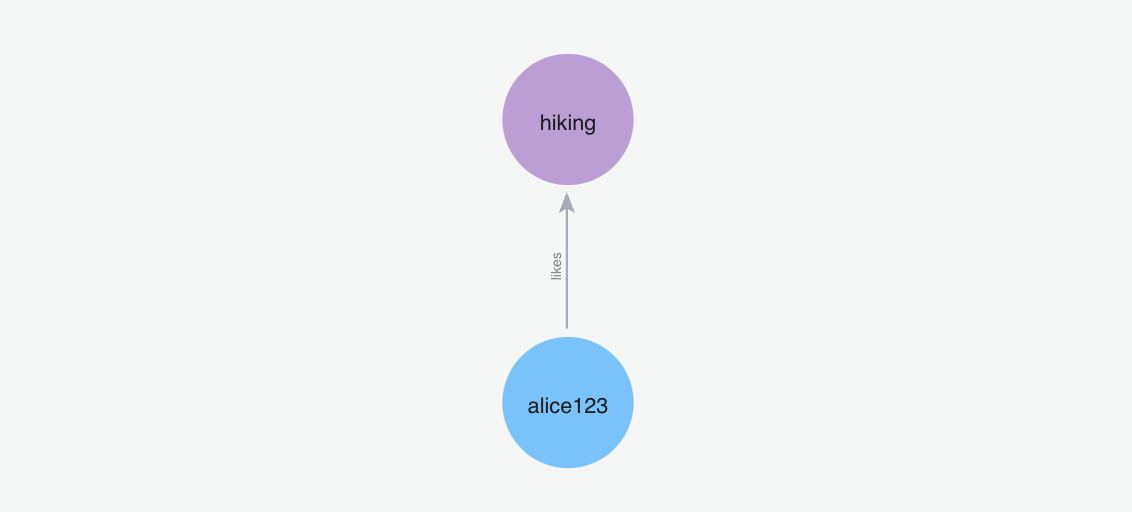
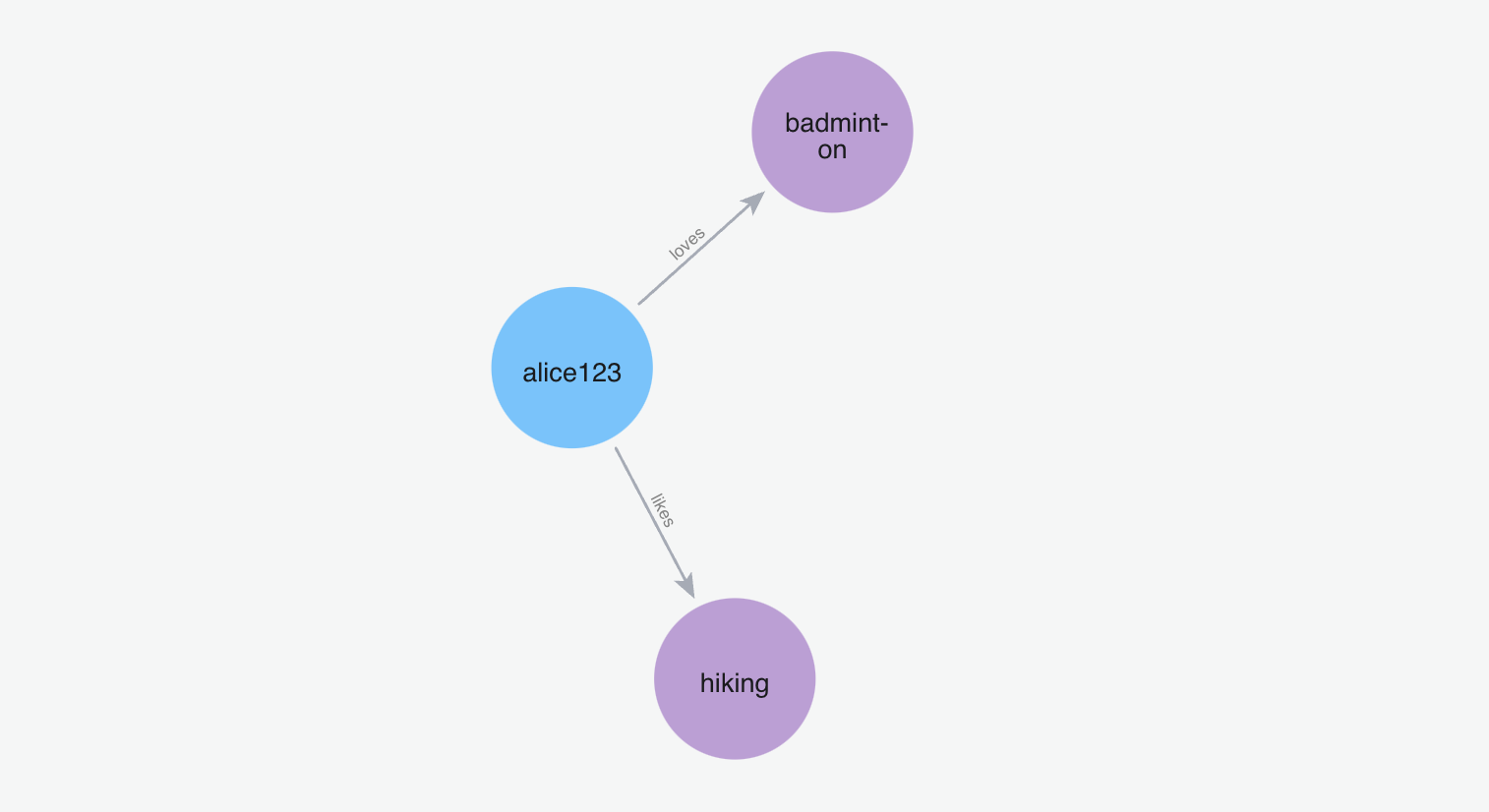
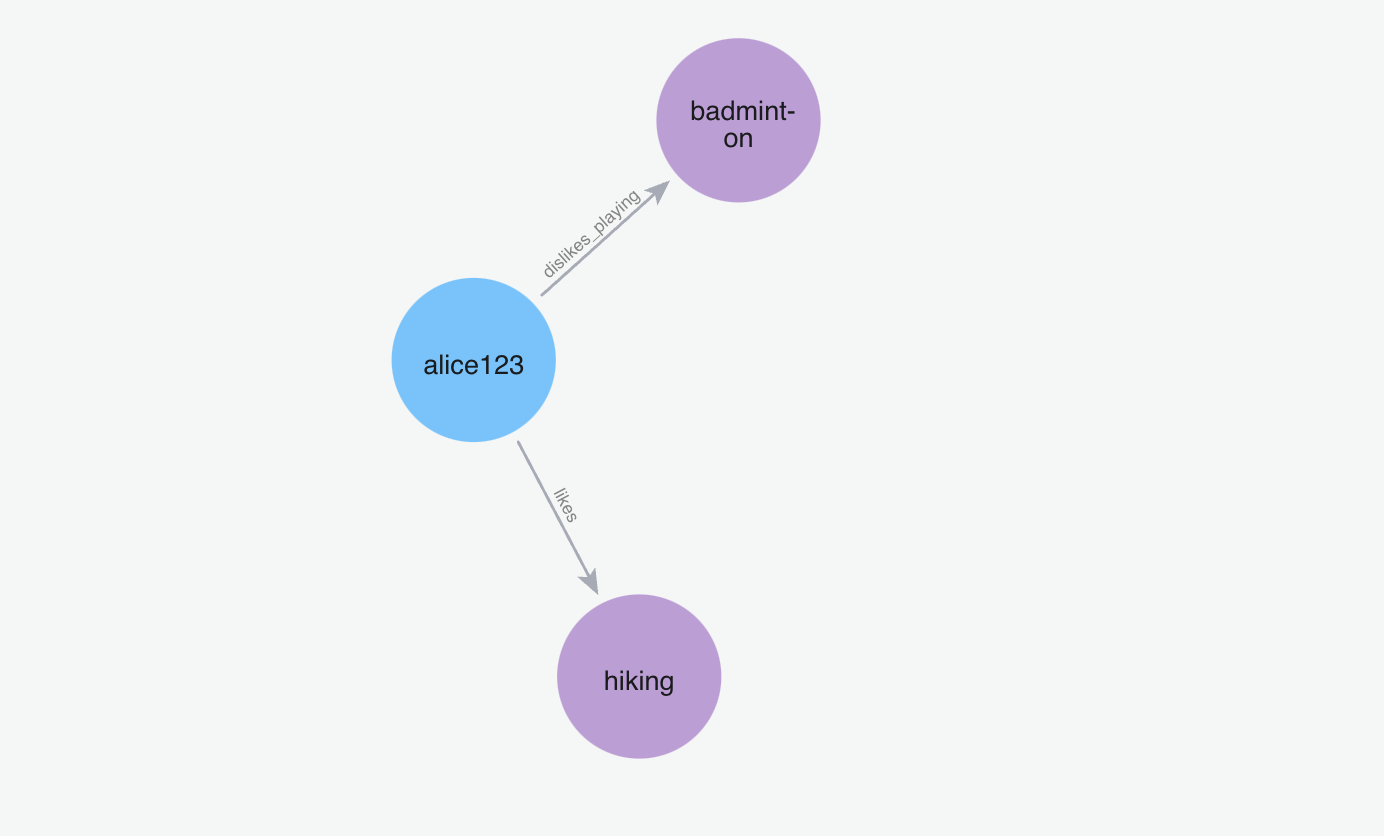
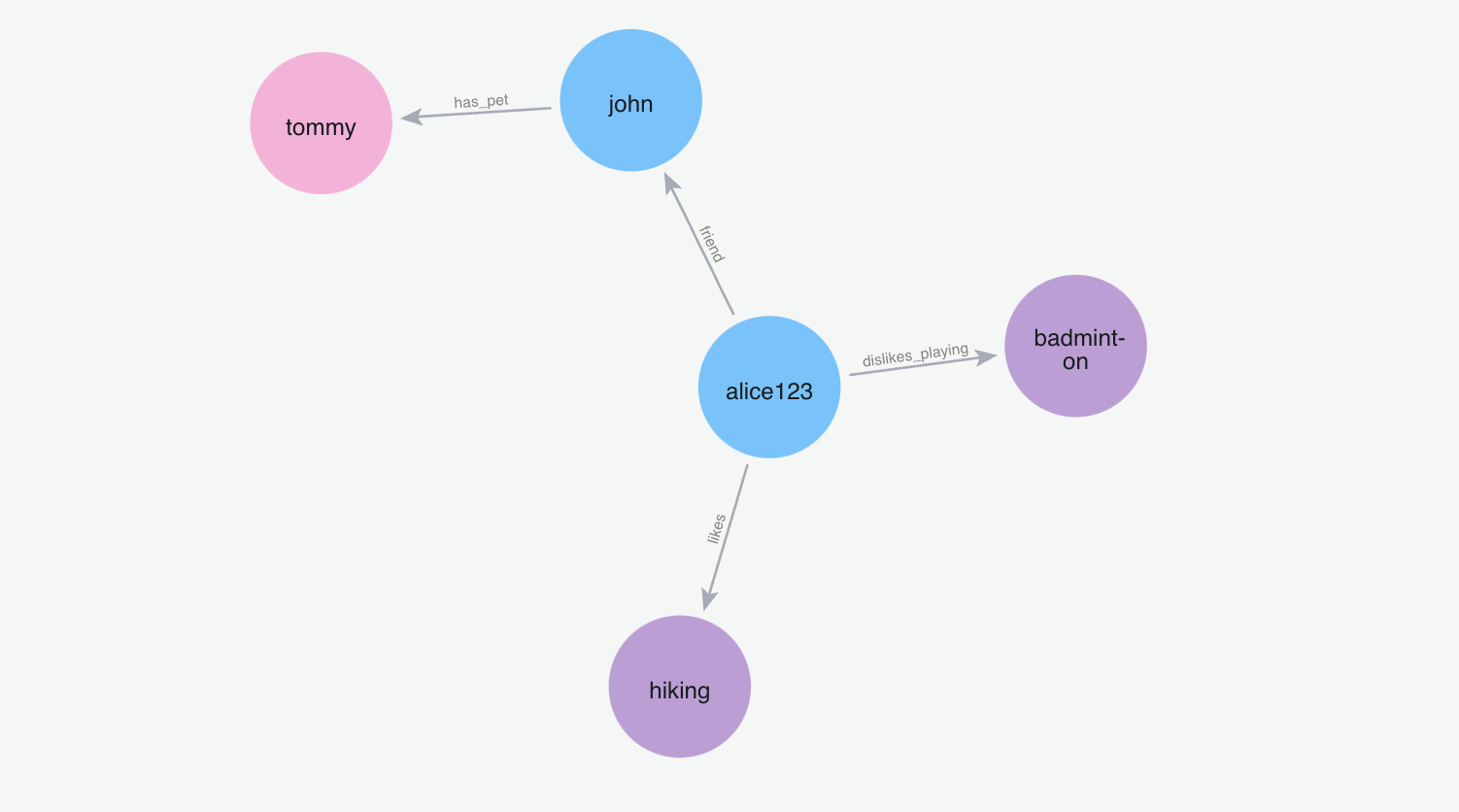
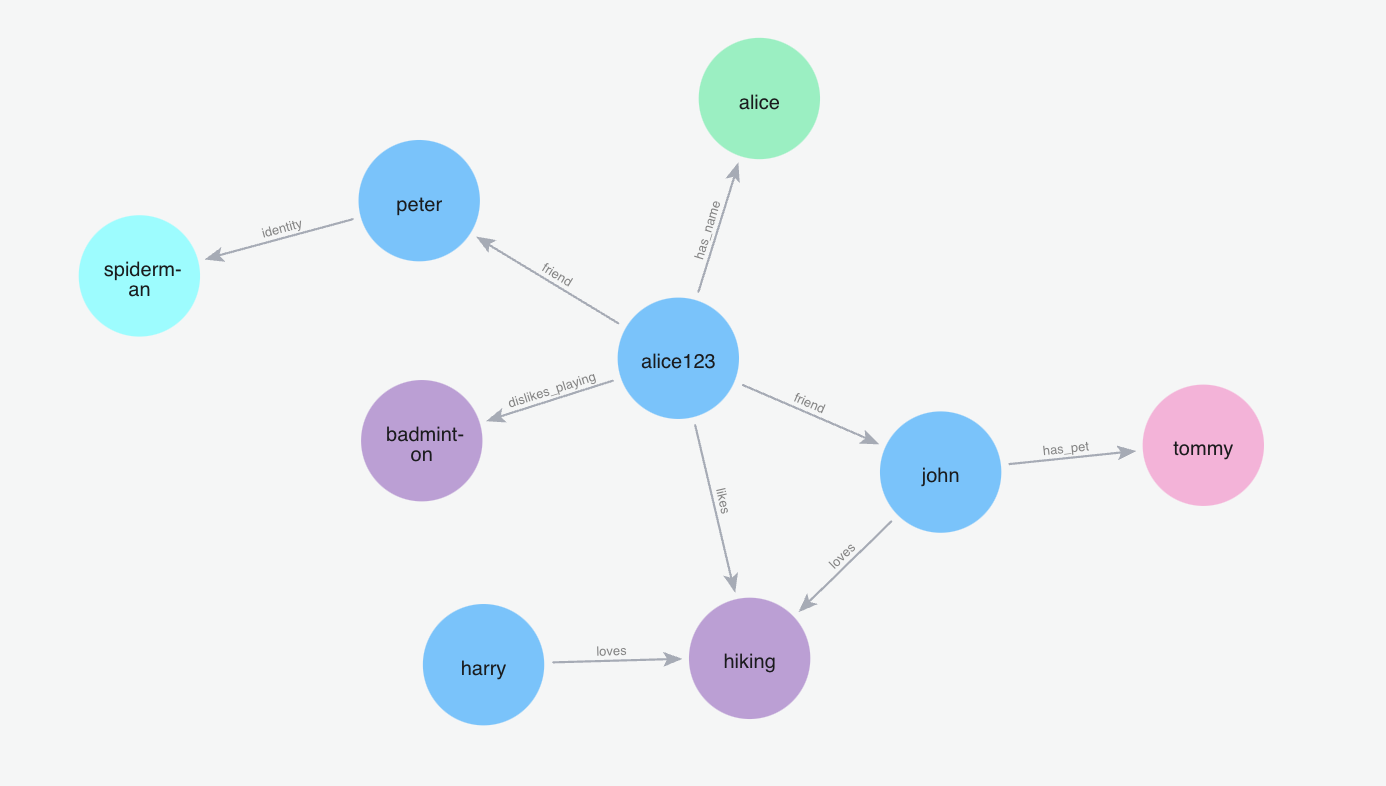
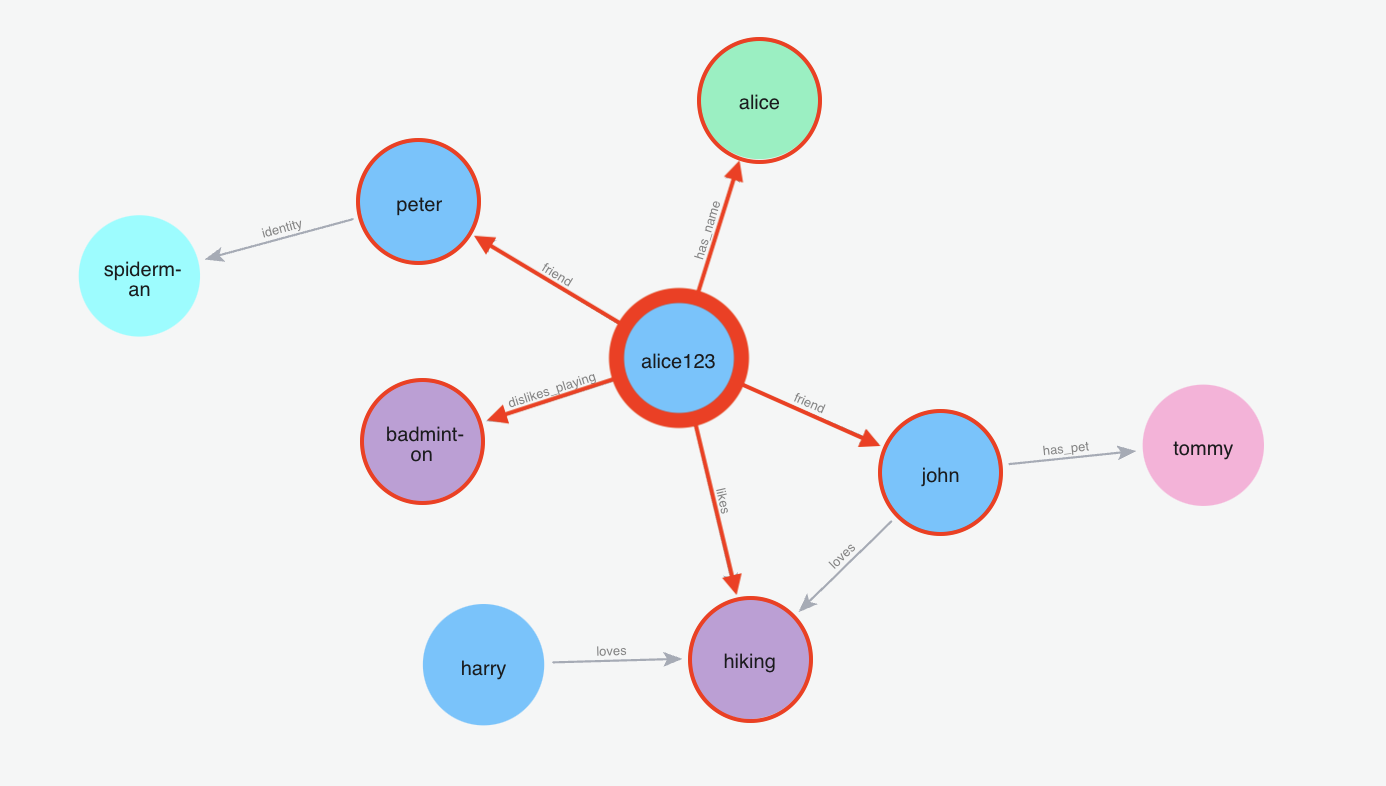
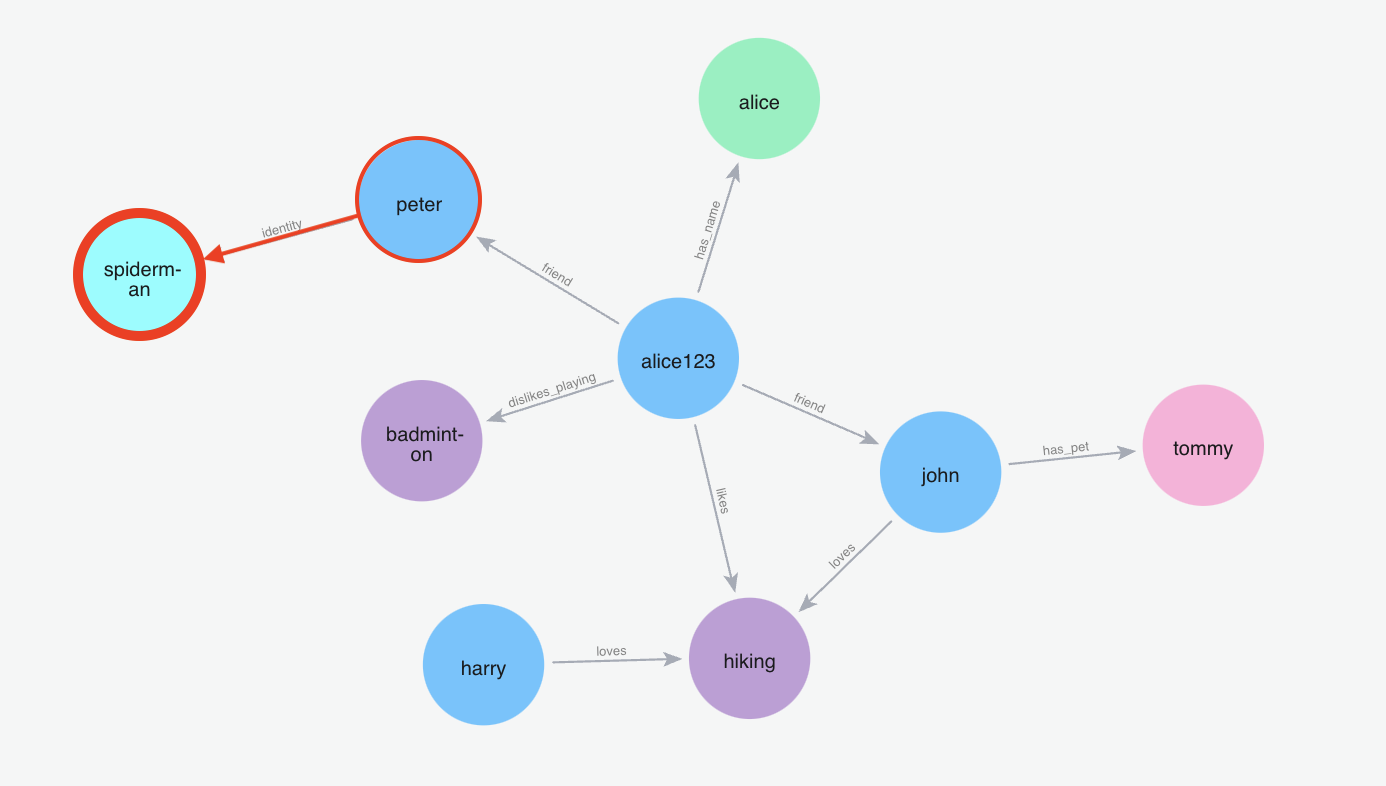
Below graph visualization shows what nodes and relationships are fetched from the graph for the provided query.
Copy
Ask AI
m.search("Who is spiderman?", user_id="alice123")
Note: The Graph Memory implementation is not standalone. You will be adding/retrieving memories to the vector store and the graph store simultaneously.
When working with multiple agents and sessions, you can use the “agent_id” and “run_id” parameters to organize memories by user, agent, and run context. This allows you to:
Create agent-specific knowledge graphs
Share common knowledge between agents
Isolate sensitive or specialized information to specific agents
Track conversation sessions and runs separately
Maintain context across different execution contexts
# Add memories for different agentsm.add("I prefer Italian cuisine", user_id="bob", agent_id="food-assistant")m.add("I'm allergic to peanuts", user_id="bob", agent_id="health-assistant")m.add("I live in Seattle", user_id="bob") # Shared across all agents# Add memories for specific runs/sessionsm.add("Current session: discussing dinner plans", user_id="bob", agent_id="food-assistant", run_id="dinner-session-001")m.add("Previous session: allergy consultation", user_id="bob", agent_id="health-assistant", run_id="health-session-001")# Search within specific agent contextfood_preferences = m.search("What food do I like?", user_id="bob", agent_id="food-assistant")health_info = m.search("What are my allergies?", user_id="bob", agent_id="health-assistant")location = m.search("Where do I live?", user_id="bob") # Searches across all agents# Search within specific run contextcurrent_session = m.search("What are we discussing?", user_id="bob", run_id="dinner-session-001")
If you want to use a managed version of Mem0, please check out Mem0. If you have any questions, please feel free to reach out to us using one of the following methods: